为什么使用pandas
为什么使用pandas?
原因如下:
- 便捷的数据处理能力,例如NaN数据处理
- 读取文件方便,可以一行代码读取
- 封装了MatplotlibNumpy的画图和计算
案例:导入import pandas as pd开始使用,安装jupter notebook中自动补全代码等相关功能拓展,安装方式见文章xxx。
首先使用NumPy库中的random.normal()函数产生一个10行5列的二维数组,其中每个元素都是从均值为0、标准差为1的正态分布中随机生成的。np.random.normal()函数的第一个参数指定随机数的均值,这里是0;第二个参数指定随机数的标准差,这里是1;第三个参数是一个元组,指定生成随机数的维度,这里是一个10行5列的二维数组。
import pandas as pd
import numpy as np
stock_change=np.random.normal(0,1,(10,5))
print(stock_change)
[[-0.8839399 0.13410133 -0.29994427 -0.42255513 -0.35435797] [-1.2541172 0.02945856 0.76384745 -1.16499618 1.43429859] [ 1.10479913 -0.61920587 -0.25956199 -0.04630725 0.65645545] [-1.05407072 -0.35426763 0.14424783 -0.00950447 0.64640135] [-0.69032064 -0.69997813 -0.53660871 -0.62647922 -0.30378882] [ 2.38129167 -0.16819386 -0.92132072 0.47600787 1.8644507 ] [ 0.07486106 1.17106617 0.49865478 0.10254686 0.56306102] [ 0.72538882 1.42147359 0.78106767 0.43830878 0.86917494] [-0.89466597 -1.14244832 0.54467935 -0.80695031 -0.22348227] [-1.80133627 1.49347643 -0.47432041 0.69327176 -0.19207681]] 问题:上述数据形式很难看到存储是什么样子的数据,也很难获取相应的数据。比如获取某个指定股票的数据,就很难获取。
给股票数据增加行列索引,显示效果更佳。
stock_day_rise=pd.DataFrame(stock_change) print(stock_day_rise)
0 1 2 3 4
0 -0.883940 0.134101 -0.299944 -0.422555 -0.354358
1 -1.254117 0.029459 0.763847 -1.164996 1.434299
2 1.104799 -0.619206 -0.259562 -0.046307 0.656455
3 -1.054071 -0.354268 0.144248 -0.009504 0.646401
4 -0.690321 -0.699978 -0.536609 -0.626479 -0.303789
5 2.381292 -0.168194 -0.921321 0.476008 1.864451
6 0.074861 1.171066 0.498655 0.102547 0.563061
7 0.725389 1.421474 0.781068 0.438309 0.869175
8 -0.894666 -1.142448 0.544679 -0.806950 -0.223482
9 -1.801336 1.493476 -0.474320 0.693272 -0.192077
增加行索引
- 构建行索引
- 增加行索引
stock_code=["股票{}".format(i+1) for i in range(10)]
print(stock_code)
['股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9', '股票10']
pd.DataFrame(stock_change,index=stock_code)--注意传递的是ndarray
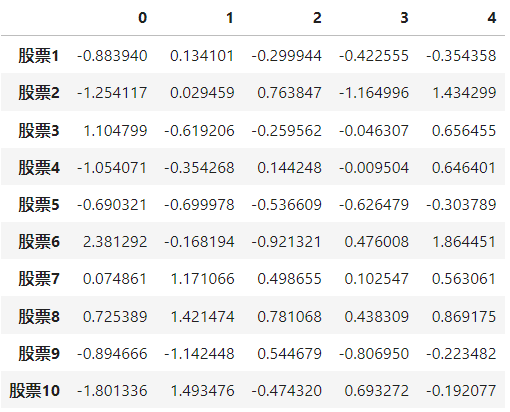
修改索引,必须整体全部修改
列索引,增加日期
股票日期是一个时间的序列,我们实现从前往后的时间还要考虑每月的总天数,不方便。使用pd.data_range():用于生成一组连续的时间序列。
date_range(start,end,period,freq),
start:开始日期
end:结束日期
period:时间天数
freq:单位默认为1天,B默认略过周末
date=pd.date_range('20190403',periods=stock_day_rise.shape[1],freq='B')
print(date)
DatetimeIndex(['2019-04-03', '2019-04-04', '2019-04-05', '2019-04-08',
'2019-04-09'],
dtype='datetime64[ns]', freq='B')
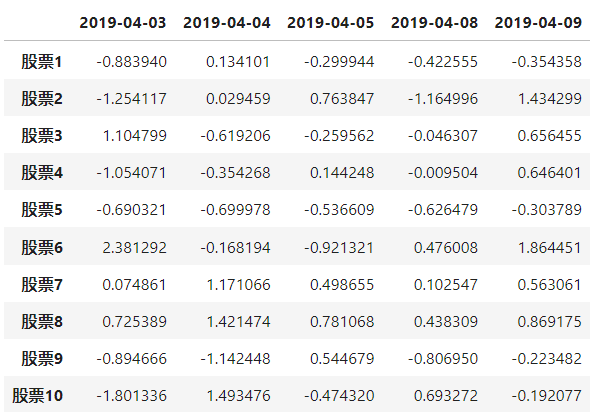
pd.DataFrame(stock_change,index=stock_code,columns=date)
关注公众号「水沐教育科技」,在手机上阅读所有教程,随时随地都能学习。内含一款搜索神器,免费下载全网书籍和视频。

微信扫码关注公众号